“딥러닝 알아듣기” 시리즈는 딥러닝의 기초 지식을 저만의 방식으로 쉽게 풀어내는 시리즈입니다. 이번 챕터에서는 PyTorch 기반 딥러닝 실습 환경을 세팅해봅니다.
2.3.1. CUDA 설치와 테스트
이제 본격적으로 딥 러닝을 공부할 준비를 해 보자. 이 시리즈에서 기준으로 삼은 실습 환경은 아래와 같으며, 이후의 모든 내용은 아래의 환경을 기준으로 설명할 것이다. 윈도우즈 운영체제에서의 실습 환경은 고려하지 않았다. 윈도우즈의 경우 설치 방법이 다르므로, 직접 CUDA 및 PyTorch까지 설치해주기 바란다.
- Ubuntu 18.04
- CUDA 9 및 cuDNN 7 버전 이상을 지원하는 NVIDIA GPU 장착 (GeForce GTX 1050 이상의 그래픽카드)
GPU가 없어도 실습 코드는 그대로 따라해볼 수 있으나, 이후 챕터에서 소개될 무거운 인공 신경망 모델에 대해서는 실행 속도가 느릴 수 있다. 만약 GPU가 없는 실행 환경이라면 이번 챕터는 건너뛰어도 좋다.
NVIDIA GPU 드라이버 설치
우분투 환경에서 NVIDIA GPU를 사용하기 위해서는 드라이버를 먼저 설치해야 한다. NVIDIA 드라이버의 설치에는 두 가지 방법이 있다.
APT를 이용한 드라이버 설치
APT는 우분투의 패키지 관리자다. APT로 드라이버를 설치하면 드라이버와 관련된 패키지 의존성을 자동으로 잘 맞추어준다는 장점이 있다. 우분투가 현재 시스템 상황에 맞게 자동으로 설치를 도와주므로, 설치가 처음인 사람들에게 추천하는 방법이기도 하다.
먼저 현재 우분투에 설치되어 있는 패키지들의 업데이트를 검색하고, 업데이트를 실행한다. 기반 패키지들의 버전을 최신으로 유지하기 위함이다.
$ sudo apt-get update
$ sudo apt-get upgrade
APT로 소프트웨어 패키지를 설치하기 위해서는 먼저 APT에 해당 패키지에 대한 Repository를 추가해주어야 한다. NVIDIA 드라이버의 Repository는 아래 명령어로 추가할 수 있다.
$ sudo add-apt-repository ppa:graphics-drivers/ppa
$ sudo apt-get update
아래 명령어를 입력해서, 현재 컴퓨터에 붙어있는 GPU와 호환되는 NVIDIA 드라이버 버전을 찾는다.
$ ubuntu-drivers devices
명령을 실행하면 다음에 보이는 결과와 같이 우분투가 현재 설치되어 있는 그래픽카드에 호환되는 추천 드라이버 버전을 자동으로 찾아준다. 사용중인 그래픽 카드를 지원하는 드라이버 중 가장 높은 버전의 드라이버를 설치한다. 보통의 경우 가장 최신 버전의 드라이버가 추천되며 recommend 표시가 붙어 나타난다.
== /sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0 ==
modalias : pci:v000010DEd00001E07sv00007377sd00001401bc03sc00i00
vendor : NVIDIA Corporation
driver : nvidia-driver-435 - distro non-free
driver : nvidia-driver-440 - distro non-free recommended
driver : xserver-xorg-video-nouveau - distro free builtin
해당 드라이버를 설치하고 우분투를 재시작한다.
$ sudo apt install nvidia-driver-440
$ reboot now
드라이버가 정상적으로 설치되었다면, 재시작된 후 터미널에서 nvidia-smi 명령으로 그래픽카드의 사용과 관련된 정보를 실시간으로 확인할 수 있다.
$ nvidia-smi
$ nvidia-smi
Fri May 29 11:44:19 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.59 Driver Version: 440.59 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 208... Off | 00000000:01:00.0 On | N/A |
| 0% 31C P8 31W / 280W | 426MiB / 11016MiB | 2% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1174 G /usr/lib/xorg/Xorg 18MiB |
| 0 1207 G /usr/bin/gnome-shell 57MiB |
| 0 1461 G /usr/lib/xorg/Xorg 162MiB |
| 0 1585 G /usr/bin/gnome-shell 93MiB |
+-----------------------------------------------------------------------------+
드라이버에 문제가 생겨 그래픽카드를 정상적으로 이용할 수 없는 경우에는 오류가 뜨며 정상적으로 실행되지 않는다. 원인은 다양하지만, 보통의 경우 아래와 같이 nvidia 드라이버와 관련된 모든 패키지를 삭제한 후 재설치하면 해결된다.
$ sudo apt remove --purge nvidia*
드라이버를 직접 다운받아 설치
APT를 이용한 설치가 정상적으로 되지 않을 경우, 드라이버를 직접 다운받아 설치하는 방안을 고려해볼 수 있다. 다음 링크의 NVIDIA 드라이버 다운로드 사이트에 접속해서, 현재 시스템의 구성에 맞는 드라이버를 직접 찾아 설치 파일을 다운로드받을 수 있다.
https://www.nvidia.co.kr/Download/index.aspx?lang=kr

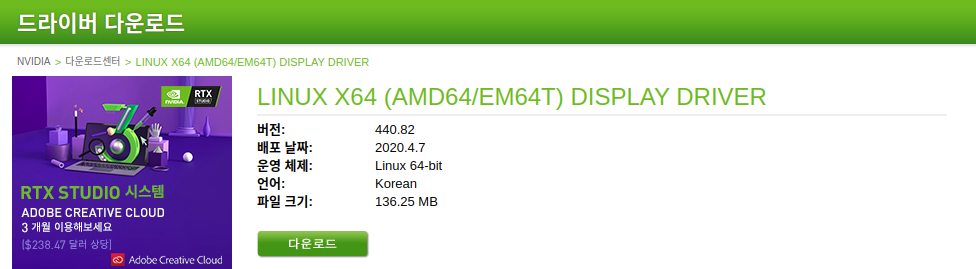
설치 파일은 .run 확장자의 파일이며, 터미널에서 실행하여 설치 프로세스를 진행할 수 있다.
CUDA 설치
CUDA는 NVIDIA사의 그래픽카드를 통한 GPGPU 가속 연산을 지원해주는 기술이다. NVIDIA는 GPU의 병렬 연산 기능을 개발자가 활용할 수 있도록 CUDA C 라는 이름의 C언어 확장을 개발하였다. CUDA C를 이용해서 GPU 메모리를 활용한 병렬 처리를 지원하는 프로그램을 작성할 수 있다. 이렇게 작성된 프로그램은 실행되는 컴퓨터에 설치된 CUDA 플랫폼을 통해 GPU를 활용한 연산을 수행한다. CUDA 플랫폼은 프로그램의 내용에 따라 GPU 메모리에 데이터를 적재하고 가져오며, 프로그램이 생성한 명령을 바탕으로 CPU가 GPU에 연산 작업을 지시할 수 있도록 돕는다.
실습 과정에서 PyTorch 딥 러닝 프레임워크를 사용할 것이다. GPU를 사용하는 PyTorch의 딥 러닝 모델 학습과 실행 환경은 내부적으로 CUDA C로 작성되어 있다. 파이썬 코드로 딥 러닝 모델과 학습을 위한 연산들을 정의해놓으면, 실행 과정에서 PyTorch가 해당 연산들을 GPU 상에서 처리할 수 있도록 만들어준다. 따라서 PyTorch를 이용해 GPU에서 딥 러닝 모델을 학습하고 실행하려면 먼저 CUDA를 환경에 설치해주어야 한다.
먼저 다음 사이트에서 현재 사용하고 있는 그래픽카드와 NVIDIA 드라이버 버전에 맞는 CUDA Toolkit의 버전을 찾는다.
https://developer.nvidia.com/cuda-downloads
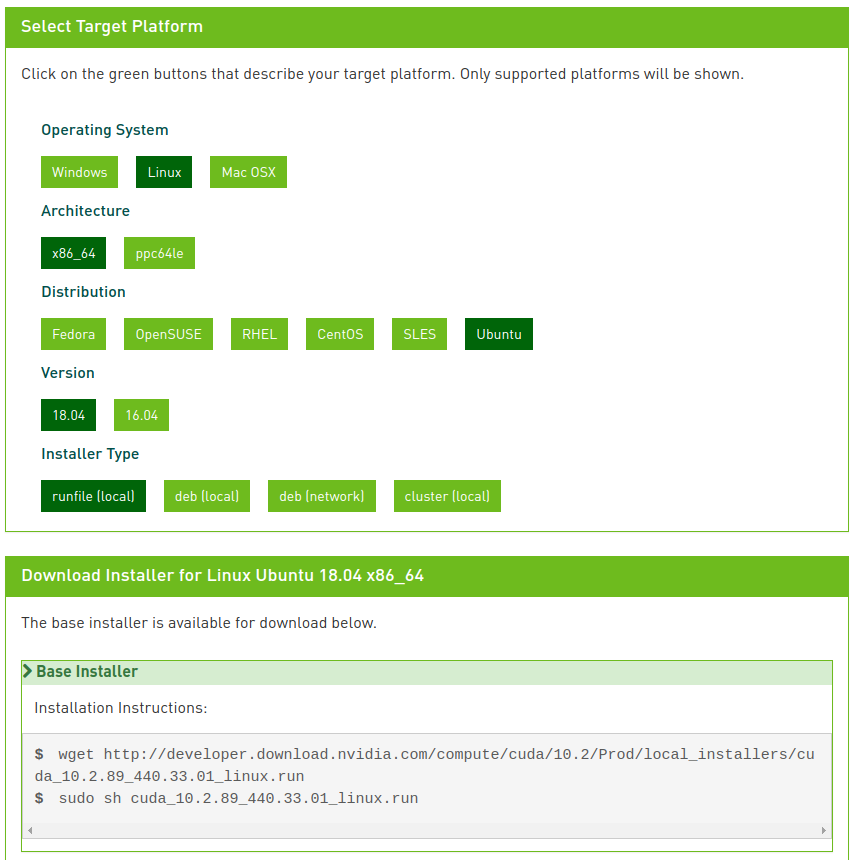
필자는 실습 환경에 맞게 64비트 우분투 18.04에 설치할 CUDA 버전을 검색하였다. 설치 파일의 형태를 로컬 환경에서 실행할 runfile로 맞춰주면 설치 프로그램을 다운받을 수 있는 명령어를 보여준다. 명령어를 순서대로 실행하여 설치 파일을 다운받고 CUDA의 설치를 진행한다.
CUDA의 설치 runfile에는 NVIDIA 그래픽 드라이버가 같이 들어있다. 우분투에 이미 NVIDIA 그래픽 드라이버가 설치되어 있다면 맨 처음 화면으로 기존 드라이버를 지우라고 권장하는 화면이 나온다. 앞서 설치한 드라이버의 버전이 현재 CUDA 설치 파일의 드라이버 버전보다 낮다면, 기존의 드라이버를 지우고 다시 CUDA와 같이 재설치해주는 것이 좋다. 그렇지 않다면 무시하고 CUDA만 설치를 진행해도 된다. 해당 버전의 CUDA 실행에 필요한 최소 그래픽 드라이버 버전을 충족시켜야 하기 때문이다. 설치 runfile의 이름에서 포함된 NVIDIA 드라이버의 버전을 확인 가능하다.
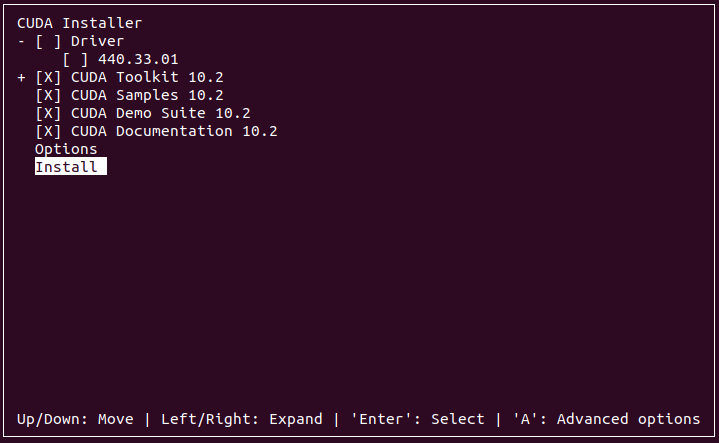
CUDA의 설치가 완료되면 아래의 커맨드들을 순차적으로 실행해서 설정을 마무리한다. 우분투의 전역에서 CUDA를 사용할 수 있도록 만들어주는 설정들이다.
$ echo "PATH=$PATH:/usr/local/cuda/bin" > ~/.bashrc
$ echo "LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib" > ~/.bashrc
$ source ~/.bashrc
cuDNN 설치
CUDA에서 더 나아가, NVIDIA에서는 CUDA를 이용해 딥 러닝 모델을 학습하고 실행하는 과정을 추가적으로 지원해주는 cuDNN 라이브러리를 개발하였다. 다양한 딥 러닝 라이브러리들이 cuDNN을 활용해 딥 러닝 모델을 실행하므로 설치해주는 것이 좋다. 다음의 사이트에 접속하여 로그인하면, 설치한 CUDA 버전에 맞는 cuDNN 라이브러리를 받을 수 있다.
https://developer.nvidia.com/rdp/cudnn-download
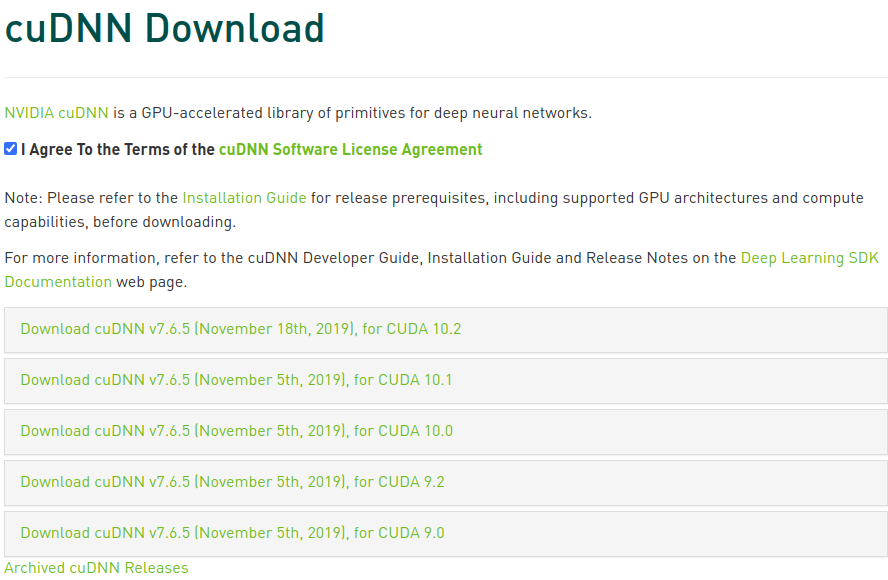
cuDNN Library for Linux를 클릭해 라이브러리를 다운받고 압축을 해제한 후, 다음의 명령을 순서대로 실행해 CUDA 내에 cuDNN 라이브러리를 포함시켜준다.
$ sudo cp cuda/include/* /usr/local/cuda/include
$ sudo cp cuda/lib64/* /usr/local/cuda/lib64
$ sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
이상으로 우분투 실습 환경에서 GPU 가속을 활용하기 위한 준비 작업이 모두 완료되었다.
2.3.2. 파이썬 설치
이 시리즈에서는 파이썬(Python) 프로그래밍 언어 기반의 딥 러닝 실습 환경을 사용할 것이다. 파이썬은 오늘날의 머신 러닝과 데이터 분석 분야에서 가장 널리 사용되고 있는 프로그래밍 언어다.
파이썬은 인터프리터 언어 이며, 문법이 다른 프로그래밍 언어들에 비해 상당히 간결한 편이다. 윈도우와 리눅스, 맥, 모바일 등 다양한 플랫폼에서 실행 가능하다.
딥 러닝의 실습에 파이썬을 사용해야 하는 이유 몇 가지를 정리해보면 아래와 같다.
-
코드를 작성하고 분석하기 편하다. 딥 러닝을 공부하면, 코드를 보고 모델의 구조를 머리속에 그려보는 등 코드를 분석할 일이 많아질 것이다. 다른 언어들에 비해 파이썬은 코드를 읽기 쉬워서, 이런 분석 작업에 힘이 덜 들어간다. 인터프리터 언어인 점도 한 몫 했지만, 파이썬의 문법 자체가 그리 어렵지 않아서이기도 하다. 물론 모든 경우에 쉬운 것은 아니다. 상황에 따라 다르고 코드에 따라 다르긴 하지만, 대부분의 상황에서는 파이썬을 사용하는 것이 생산성에 더 큰 도움이 된다는 것이다.
-
매우 다양한 데이터 분석과 머신 러닝 라이브러리가 제공된다. 구글과 같은 거대 기업이 밀어주고 있는 라이브러리부터, 개인이 편의를 위해 제작한 라이브러리까지 매우 다양한 라이브러리가 존재한다. 미리 구현되어 성능이 검증된 라이브러리들을 잘 활용하면 코딩에 고생하지 않아도 멋있는 알고리즘을 구현할 수 있다. 단순 수치 계산을 도와주는 라이브러리부터 머신 러닝 연습을 위한 가짜 학습 데이터를 만들어주는 라이브러리까지, 잘 골라 쓰기만 하면 코딩 시간을 크게 줄일 수 있다.
또한 이 많은 라이브러리들은 pip 라고 불리는 패키지 매니저가 알아서 잘 관리해주므로, 그저 잘 가져다 쓰기만 하면 된다.
-
아이디어의 구현에 걸리는 시간을 줄여준다. 1번, 2번 이유와 관련된 맥락이다. 코드의 작성과 분석이 쉽고 도움을 주는 라이브러리도 정말 많아서, 새로운 아이디어가 떠올랐을 때 쉽게 구현해볼 수 있다. 코드의 확장성도 정말 좋아서, 대부분의 딥 러닝 논문들은 새로운 아이디어나 모델을 구현할 때 파이썬 코드로 구현 후 공유하기도 한다.
-
유명한 IT 기업들이 많은 오픈 소스 프로젝트를 파이썬으로 진행하고 있다. 딥 러닝 분야의 특성 상, 구글, 페이스북, 아마존과 같은 거대한 IT 기업들의 행보가 딥 러닝 분야 전체를 뒤흔드는 경우가 많다. 뒤쳐지지 않고 시대를 따라가려면 공룡들의 행보를 따라가는 것이 중요하다. 텐서플로우, 파이토치 등의 유명한 딥 러닝 라이브러리들도 모두 파이썬이 기반 언어이다.
-
사용자 층이 정말 풍부하고, 커뮤니티가 활성화되어 있다. 어린 학생들부터 현업의 시니어 개발자까지 다양한 사람들이 오늘도 파이썬을 사용하고 있다. 특히 많은 딥 러닝 개발자들이 주력 언어로 파이썬을 사용하고 있기도 하다. 수많은 구글 검색을 해가며 공부해야 하는 우리와 같은 입장에서, 파이썬의 이런 사용 환경은 정말 축복이라고 해도 좋을 것 같다. 파이썬은 커뮤니티 문화가 매우 활성화된 언어라서 배우기도 쉽고, 사람들과 의견을 공유하기도 좋다.
파이썬 설치
파이썬에 대한 칭찬은 이쯤 하고, 이제 직접 우분투 환경에 파이썬을 설치해서 코드를 작성해보자. 이 시리즈에서는 파이썬 3.7 버전을 사용해 개발 환경을 구축할 것이다.
먼저 우분투에서 다양한 프로그램을 설치하고 빌드하는데 필요한 기본적인 툴들을 설치해주자.
$ sudo apt install build-essential
아래의 커맨드를 입력해 우분투의 패키지 관리자인 apt에 파이썬을 추가해주자. 커맨드를 실행하면 여러 파이썬 버전이 포함된 ‘레포지토리’가 apt에 추가된다. update 명령을 통해 apt에 파이썬 3.7에 대한 정보를 추가해준다.
$ sudo add-apt-repository ppa:deadsnakes/ppa
$ sudo apt update
파이썬 3.7버전과, 파이썬의 패키지 관리자인 pip를 차례대로 설치해준다.
$ sudo apt install python3.7 python3-pip
$ python3.7 -m pip install pip3
파이썬의 설치가 완료되었다. python 커맨드가 기본적으로 3.7버전의 파이썬을 바라보게 하기 위해, 다음의 커맨드를 실행해준다.k
$ sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.7 1
실습 관련 패키지 설치
파이썬으로 딥 러닝을 실습하면서 자주 사용하게 되는 몇 가지 파이썬 라이브러리들을 설치해야 한다. 다음의 라이브러리들은 이 책이 아니더라도 앞으로 자주 사용하게 될 것이므로, 미리 설치해두고 가는 것이 좋다.
- numpy : 추가적인 설명이 필요없는 파이썬의 필수 패키지다. 수치와 행렬 계산을 위해 최적화된 다양한 함수들을 제공해준다. 이후에 설치할 많은 패키지들이 numpy의 행렬 데이터를 기본적으로 사용하므로 필수 패키지이다.
- matplotlib : 데이터의 시각화를 전문적으로 수행하는 패키지이다. 딥 러닝 모델을 학습시키다 보면, 데이터셋의 시각화나 학습 중간의 진행 상황 확인과 같이 무엇인가를 플롯(plot) 위에 나타내야 할 경우가 자주 생긴다. matplotlib는 간단하게 다양한 데이터를 시각화하도록 돕는다. 이 책의 대부분의 그래프도 이 패키지를 사용해서 생성하였다.
- opencv-python : 대표적인 오픈소스 컴퓨터 비전 라이브러리인 OpenCV의 파이썬 라이브러리이다. OpenCV는 이미지 처리부터 시작해서 행렬 연산, 컴퓨터 비전의 다양한 분야에 폭넓게 사용되므로, 딥 러닝 학습에 전반에 있어서 많이 활용될 것이다.
- scipy : scipy는 데이터의 과학적인 분석과 수학적 계산을 도와주는 패키지이다. 머신 러닝 구현에 도움이 되는 기능도 다수 포함되어 있다.
- scikit-learn : 머신 러닝 실습을 위한 다양한 보조 기능들이 포함된 패키지이다. 사이킷런으로 직접 머신 러닝 알고리즘을 구현할 수도 있다. 외부 데이터셋을 불러오거나 임의의 데이터셋을 생성하는 기능도 매우 유용하다.
파이썬의 패키지들은 다음과 같이 pip를 이용해 설치할 수 있다.
$ pip install numpy
$ pip install matplotlib
$ pip install opencv-python
$ pip install scipy
$ pip install scikit-learn
각 패키지의 사용법에 대한 자세한 설명은 하지 않고 넘어가겠다.
2.3.3. PyTorch 설치
이 시리즈에서는 실습을 위한 딥 러닝 프레임워크로 PyTorch를 사용한다. 다른 프레임워크보다 상대적으로 쉽게 익숙해질 수 있고, 코드를 이해하기 가장 쉬울 듯 하여 PyTorch로 선정했다. 우분투 및 NVIDIA GPU를 사용하는 환경에서 PyTorch를 설치하고 테스트해보자.
PyTorch 공식 사이트에서 현재 환경에 맞는 PyTorch 설치 명령어를 찾을 수 있다.
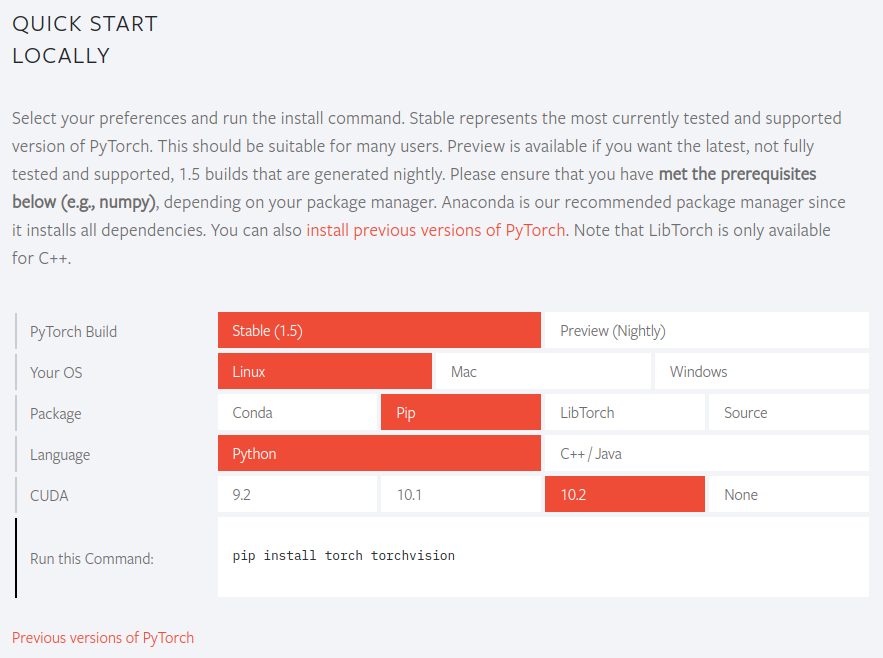
안정화(Stable) 빌드를 선택하고 현재 환경에 맞게 선택하면, 현재 환경에 PyTorch를 설치할 수 있는 명령이 나온다. 명령을 실행해 실습 환경에 맞는 PyTorch를 설치한다. 명령을 실행하면 PyTorch 패키지와 딥 러닝 학습을 위한 보조 도구들이 들어있는 Torchvision 패키지를 동시에 설치한다.
$ pip install torch torchvision
정상적으로 설치가 완료되면 파이썬에서 import torch 명령으로 PyTorch 패키지를 불러올 수 있다. 또한 torch.cuda.is_available 함수를 통해 현재 PyTorch가 GPU 자원을 활용 가능한지 확인할 수 있다. GPU가 설치되어 있는 환경인데 True로 나타나지 않는다면 NVIDIA 드라이버 또는 CUDA가 알맞게 설치되었는지 다시 한번 확인해보아야 한다. GPU가 없는 환경은 False로 나타나는 것이 당연하며, 이 경우 CUDA 텐서와 같이 CUDA와 관련된 PyTorch의 GPU 연산 가속 기능들을 사용할 수 없다.
Python 3.7.7 (default, Mar 10 2020, 15:16:38)
[GCC 7.5.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.cuda.is_available()
True
이로써 실습을 위한 모든 환경 구성이 완료되었다. 다음 챕터부터 본격적으로 딥 러닝 모델을 학습시켜보도록 하자.