“딥러닝 알아듣기” 시리즈는 딥러닝의 기초 지식을 저만의 방식으로 쉽게 풀어내는 시리즈입니다. 이번 챕터에서는 손글씨 숫자 데이터셋인 MNIST를 이용해 본격적으로 심층 신경망을 구현해 봅니다.
앞선 챕터들에서 종류별로 간단하게 신경망 모델들을 학습하면서 딥 러닝 모델 학습의 핵심 개념들을 같이 짚어보았다. 이번 챕터에서는 더욱 현실에 가까운 숫자 손글씨 데이터를 분류하는 복잡한 모델을 학습하면서, 딥 러닝 모델 학습 과정에서 고려해야 할 다양한 문제 상황을 이해해보도록 하자. 또한 모델을 저장하고 불러오는 등, 학습 과정에서 도움이 될 만한 PyTorch의 몇 가지 기능들을 알아보도록 하자.
3.5.1. 모델 학습 계획 세우기
MNIST 데이터셋
머신 러닝 분야에는 유명한 스타 데이터셋 들이 있다. 머신 러닝의 연구 또는 학습 목적으로 널리 쓰이는 데이터셋인데, 분야별로 성능 평가를 위한 지표로 활용되기도 한다. 이번 챕터에서 소개하는 MNIST 데이터셋도 가장 유명한 스타 데이터셋 중 하나이다.
MNIST는 손으로 쓴 숫자 이미지들을 7만장 모은 데이터셋이다. 트레이닝 데이터 6만장과 테스트 데이터 1만장으로 구성되어 있으며 각각의 이미지는 28x28 크기이다. 적당히 작은 이미지 크기와 다양한 숫자 모양의 분포를 가진 데이터셋으로, 여러 분야의 딥 러닝 모델을 학습하고 검증하기 위한 가장 기본적인 데이터셋으로 사용된다. 각각의 이미지는 다음과 같이 생겼다.

실제로 모은 손글씨 숫자를 정제하고 가운데로 정렬한 후, 사진 크기를 동일하게 맞추고 흑백으로 변환한 이미지이다. 이미지가 크지 않으면서 데이터가 너무 다양하게 분포되어있지도 않아 여러모로 사용하기 좋은 데이터셋이다. 데이터의 분포가 다양하지 않다는 것은 각 숫자에 해당하는 손글씨 그림들의 모양이 대부분 크게 빗나가지 않는 수준이라는 이야기이다.
문제 정의
MNIST 데이터셋을 활용할 수 있는 방법은 정말 많지만, 가장 기본적으로 손글씨 숫자를 보고 무슨 숫자인지 알아맞추는 다중 분류를 생각해볼 수 있다. 지금까지 우리가 다뤄본 데이터셋 중 가장 현실과 가까운 문제인 듯 하다. 이번 챕터에서는 각각 이미지 형태로 준비된 MNIST 데이터셋을 불러와서, 손글씨 숫자를 분류하는 다중 분류 모델을 만들어 보자.
3.5.2. 모델 정의하고 학습하기
데이터 준비하기
먼저 이미지 데이터를 읽어오는 방법을 알아보자. 각각의 손글씨 숫자 이미지는 jpg 파일 포맷이므로, 파이썬으로 이미지를 읽어와서 모델에 입력할 수 있는 형태로 만들어주어야 한다. OpenCV의 함수를 이용하여 이미지 한 장을 샘플로 불러와 보자. cv2.imread 함수를 사용해서 이미지를 불러올 수 있다. 불러온 이미지는 numpy 배열 형태이다. cv2.imshow 함수를 이용해 이미지 배열을 직접 화면에 띄워볼 수 있다.
image_filename = 'datasets/mnist/mnist-in-image/train/00000.jpg'
image = cv2.imread(image_filename)
print(image.shape) # 이미지 배열의 모양
cv2.imshow('MNIST image', image)
cv2.waitKey() # 아무 키나 입력하면 이미지 창 사라짐
코드를 실행하면 불러들인 이미지가 화면에 뜨며, 이미지 배열의 모양을 다음과 같이 확인할 수 있다.

(28, 28, 3)
많은 경우 이미지 데이터의 모양은 가로(Width), 세로(Height), 채널(Channel) 의 세 가지 요소로 표현된다. 가로와 세로는 익히 알고 있듯이 이미지의 평면적인 크기를 나타내는 지표이다. 채널은 색 공간(Color Space)의 구성 요소 갯수를 의미한다. 하나의 예로, RGB 색 공간으로 표현되는 이미지의 채널은 Red, Green, Blue 세 개의 채널을 가진다. RGB로 표현되는 이미지에서 픽셀의 색깔은 Red, Green, Blue 값들의 조합으로 이루어지기 때문이다. YUV로 표현되는 이미지 또한 세 개의 채널을 가진다. 흑백 이미지의 경우 검정과 흰색 사이에서 픽셀의 밝기만 조절해도 모든 색을 나타낼 수 있으므로 채널이 한 개이다.

불러온 이미지의 모양이 (28, 28, 3)이라는 것은, 세로로 28픽셀, 가로로 28픽셀 크기의 이미지이고 한 픽셀당 3개의 값으로 구성되었다는 의미이다. OpenCV로 이미지를 불러올 때 따로 설정해주지 않으면 이미지를 BGR 포맷 으로 불러온다. 픽셀당 세 개의 값이 필요하다는 이야기이다. 따라서 불러온 이미지의 채널 갯수는 3이다. OpenCV에서 이미지의 기본 색 포맷은 RGB가 아닌 BGR임에 항상 주의해야 한다. 각각의 색상 값은 1바이트로 0에서 255 사이의 정수 값이다.
하지만 앞서 확인했다시피 우리가 학습시킬 MNIST 데이터셋의 이미지는 흑백이다. 어차피 각 픽셀마다 B, G, R 모든 채널의 색상 값이 동일하다. 그러므로 이미지를 픽셀마다 하나의 색상 값만을 가지는 흑백 이미지로 바꾸어줄 필요가 있다. cv2.cvtColor 함수를 이용해서 흑백 이미지로 변환한다.
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
print(image.shape) # 이미지 배열의 모양
BGR 포맷의 이미지를 흑백으로 변환한 후 다시 이미지 배열의 모양을 출력해 보면, 픽셀마다 세 개씩의 색깔 채널이 하나의 흑백 채널로 합쳐진 것을 볼 수 있다.
(28, 28)
픽셀마다의 B, G, R 세가지 색상 정보를 모두 유지한다면, 입력 데이터에서 얻을 수 있는 정보의 양이 흑백 이미지보다 세 배로 많으니 더욱 학습하기 좋을 듯 하다. 하지만 MNIST 이미지 자체가 이미 흑백이라서 세 가지 색깔 정보를 같이 취했을 때의 이점이 따로 없으므로, 모델의 연산량을 줄이기 위해 흑백 이미지로 변환해주는 것이 옳은 선택이다. 학습할 이미지가 컬러 이미지라면 당연히 그대로 놔두는 것이 좋다.
이미지를 불러오기는 했지만 우리 모델에 바로 입력할 수가 없다. 학습시킬 다중 분류 모델은 1차원의 벡터 입력만 받아들일 수 있지만, 이미지는 아직도 2차원 배열 형태이기 때문이다. 따라서 2차원의 이미지를 1차원 벡터로 변환해야 한다. 가장 쉽게 생각해볼 수 있는 방법은, 단순히 이미지 상에서 배열된 순서대로 픽셀 값을 1차원 벡터에 나열하는 것이다.

numpy.reshape 함수로 배열의 모양을 2차원에서 1차원으로 변환할 수 있다.
vec_shape = (28*28) # 변환할 이미지의 모양 : (이미지 높이 * 이미지 너비)
image = np.reshape(image, vec_shape) # vec_shape 모양으로 이미지 변환
print(image.shape)
reshape 함수의 두 번째 인자에 변환 후 배열의 모양을 튜플 형태로 넣어준다. 이미지 높이와 이미지 너비를 곱한 만큼의 길이를 가지는 1차원 벡터로 변환할 것이므로 값이 한 개인 튜플을 넣었다. 변환된 배열의 모양을 확인해보면, 28 x 28 = 784로 예상한 길이의 1차원 벡터가 된 모습을 확인할 수 있다.
(784,)
이미지에서 각각의 픽셀 값을 하나의 독립된 특징 값으로 이해할 수 있다. 한 장의 이미지를 784개의 독립된 특징을 가진 입력 벡터로 만들어낸 것이다. 모델은 그저 길이가 784인 입력 벡터를 0부터 9까지 10개의 클래스로 나누도록 학습하지만, 모델의 분류 결과를 모델 밖에서 원본 이미지와 대조해보면 실제로 손글씨 숫자를 분류한 결과를 볼 수 있다. 엄밀히 말하면 이 과정은 이미지를 1차원 벡터로 펴서 보는 것이므로 이미지 자체를 이해하는 것은 아니다. 이미지의 지역적인 특징을 제대로 이해할 수 있는 방법은 이후 챕터에서 자세히 다뤄볼 것이다.
마지막으로 입력 데이터를 정규화한다. 지금은 픽셀 값이 0부터 255 사이의 넓은 범위를 가진 정수 값이다. 이를 0에서 1 사이의 값을 가지는 실수 값으로 정규화한다. 모든 픽셀 값을 실수 데이터형으로 변환 후, 최댓값이 255임이 보장되어 있으므로 Min-Max Scaler 대신 단순하게 255로 나눈 값을 사용하겠다.
image = image.astype('float32') / 255.0
이제 위와 같은 방법으로 이미지를 불러와 모델에 제공하는 Dataset을 만들자. 이미지에 맞는 정답 레이블 데이터도 같이 불러와야한다. 학습 데이터셋과 검증 데이터셋의 정답 레이블이 각각 train_labels.txt와 val_labels.txt에 정리되어 있다.
00000.jpg 7
00001.jpg 2
00002.jpg 1
00003.jpg 0
00004.jpg 4
...
MNIST 데이터셋의 이미지를 불러와 784 길이의 입력 벡터를 만들고, 정답 레이블과 같이 제공하는 Dataset을 구현한다.
class MNISTDataset(Dataset):
def __init__(self, dir, label_filename):
self.dir = dir # 이미지가 저장된 디렉터리
self.label_filename = label_filename # 정답 레이블 텍스트 파일 이름
self.images, self.labels, self.data_count = self.data_reader()
def __len__(self):
return self.data_count
def __getitem__(self, idx):
image = cv2.imread(os.path.join(self.dir, self.images[idx]))
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = np.reshape(image, (28*28)).astype('float32') / 255.0 # 28 x 28 -> 784
label = self.labels[idx]
image = torch.as_tensor(image)
label = torch.as_tensor(label).long()
return image, label
def data_reader(self):
images = labels = []
label_file = open(self.label_filename, 'r')
label_lines = label_file.readlines()
for line in label_lines:
image = line[:-1].split(' ')[0]
label = int(line[:-1].split(' ')[1])
images.append(image)
labels.append(label)
return images, labels, len(images)
모델과 손실 함수 정의하고 학습하기
입력 데이터의 크기 자체가 매우 커졌고, 분류할 레이블의 수도 10개로 많다. 훨씬 복잡해진 입력 데이터의 특징을 이해하려면 모델 또한 깊고 넓어져야 한다. 일단 세 개의 레이어만 넓게 쌓아서 간단히 분류 모델을 만들어 학습시켜보자.
model = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
점점 작아지는 레이어들을 쌓아서 입력 데이터의 특징을 압축한다. 중간 레이어의 노드 갯수인 256은 아무런 기준 없이 경험적으로 잡은 숫자이다.
모델 최적화를 실행하는 함수를 구현한다.
def train_single_epoch(model, optimizer, train_dataset, batch_size):
lf = nn.CrossEntropyLoss()
dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
loss_sum = 0.0
for batch_num, samples in enumerate(dataloader):
x_data, y_data = samples
predict = model(x_data)
loss = lf(predict, y_data)
loss_sum += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss = loss_sum / (batch_num + 1)
print('Epoch average loss : {}'.format(avg_loss))
loss_sum = 0.0
함수 밖에서 모델과 옵티마이저를 정의하고 학습 데이터셋을 만든 후 train_single_epoch 함수에 입력해서 모델의 최적화를 진행한다. 어떤 숫자에 해당하는 손글씨인지 다중 분류하는 모델을 학습해야 하므로 손실은 다중 분류를 위한 교차 엔트로피로 계산한다. 학습 과정은 앞선 챕터에서 구현했던 다중 분류기 학습 과정과 다르지 않다.
옵티마이저를 설정하고 학습 데이터셋을 불러온 후, 정해진 에폭 수만큼 최적화 반복을 실행한다. 옵티마이저는 확률적 경사하강법을 사용하며, 학습률은 0.001이다. 에폭 수는 100으로 설정한다.
optimizer = torch.optim.SGD(model.parameters(), lr=0.001) # 최적화 옵티마이저 설정
batch_size = 256
max_epochs = 100
train_dataset = MNISTDataset('./assets/datasets/mnist/mnist-in-image/train', './assets/datasets/mnist/mnist-in-image/train_labels.txt')
# 정해진 에폭 수만큼 전체 학습 데이터셋을 돌며 최적화 진행
for epoch in range(max_epochs):
print('Epoch {}'.format(epoch))
train_single_epoch(model, optimizer, train_dataset, batch_size) # 한 에폭 최적화 진행
학습을 실행해보면 손실이 떨어지며 최적화가 잘 진행되는 것을 볼 수 있다.

학습한 모델로 추론 실행하기
학습한 모델을 실제로 실행할 수 있도록 추론 함수를 구현한다. 손글씨 숫자 이미지를 모델에 입력해서 0부터 9 사이의 숫자 중 하나로 판단해 출력하는 함수다.
import torch.nn.functional as F
def inference(model, data):
preds = model(data) # 모델의 출력을 얻는다.
preds = F.softmax(preds, dim=1) # 모델에는 Softmax가 없으므로 따로 Softmax를 적용한다.
argmax_preds = preds.argmax(dim=1) # 출력 벡터에서 가장 값이 큰 인덱스를 찾는다.
return argmax_preds
소프트맥스 함수를 따로 적용해주어야 함에 주의해야 한다. 모델을 학습할 때에는 PyTorch의 nn.CrossEntropyLoss()가 손실을 계산하면서 소프트맥스 함수를 적용해주었기 때문에 신경쓰지 않았지만, 실제로 모델에는 소프트맥스 함수가 없는 상태이다. 그래서 모델로 실제 추론하는 함수를 구현할 때는, torch.nn.functional.softmax 함수를 사용해 모델의 결과에 소프트맥스 함수를 적용해주어야 한다.
모델 성능 평가하기
학습한 MNIST 분류 모델의 성능은 간단히 분류 정확도로 평가해보도록 하자. 모델로 추론을 실행하는 함수 inference는 구현했으니, 추론 결과와 정답 데이터를 비교해서 정확도를 계산하는 함수를 구현한다.
def calc_accuracy(inf_result, y_data):
correct_count = 0
bsize = len(inf_result)
for i in range(bsize):
if inf_result[i] == y_data[i]: # 모델의 추론이 맞았을 경우
correct_count += 1
avg_accuracy = float(correct_count) / float(bsize) # 정확도 계산
return avg_accuracy
모든 평가 데이터셋에 대해 평균 정확도를 계산하는 평가 함수를 만들어 평가를 실행해보자. 평가 데이터 전체를 한번에 돌리기에는 무리가 있으므로, 검증 데이터셋을 적당히 1천개씩 끊어와서 각각 평균 정확도를 구한 후 전체 평균 정확도를 다시 구하는 방법으로 구현한다.
def test_single_epoch(model, val_dataset):
dataloader = DataLoader(val_dataset, batch_size=1000, shuffle=True)
avg_accuracy = 0.0
for batch_num, samples in enumerate(dataloader):
x_data, y_data = samples
preds = inference(model, x_data)
avg_accuracy += calc_accuracy(preds, y_data)
print(batch_num, avg_accuracy)
print('Accuracy: {}'.format(avg_accuracy / (batch_num + 1)))
검증 데이터셋에서 배치를 1000개씩 연속으로 가져와 모든 분류 결과를 구하고, 평균 정확도를 계산한다. 필자가 학습한 모델은 약 0.8961의 정확도를 보였다.
Accuracy: 0.8961
아무런 추가적인 방법을 쓰지 않고 단순히 작은 모델의 학습만으로 89%가 넘는 검증 데이터의 분류에 성공한 것은 대단한 결과다. 우리 모델이 손글씨 이미지를 어느 정도 분류할 수 있는 능력이 된다는 의미이기 때문이다. 우리는 드디어 딥 러닝으로 무엇인가 눈으로 와닿는 결과를 보는 데에 성공했다. 앞으로 학습을 더 빠르게 하고 모델의 성능을 강력하게 만들 수 있는 다양한 학습 기술들을 공부하고 나면, MNIST 분류기의 성능을 99% 가까이 올릴 수 있을 것이다.
CUDA로 학습 가속하기
GPU가 설치되어 있는 실습 환경이었어도 앞의 학습 코드는 GPU를 활용하지 않아 속도가 상대적으로 느렸을 것이다. PyTorch에서 GPU 가속을 사용하려면 PyTorch가 만드는 모든 모델과 텐서를 GPU 메모리에 올리도록 강제해주어야 한다. GPU를 활용하기 전에 현재 PyTorch가 CUDA를 이용한 GPU 가속을 사용할 수 있는 상태인지 항상 확인하고 넘어가야 한다.
print(torch.cuda.is_available()) # True일 경우 CUDA 사용 가능
대부분 PyTorch의 내장 함수인 cuda()로 데이터를 간단히 GPU에 올릴 수 있다. 먼저 모델을 GPU에 올려보자.
model = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
model = model.cuda()
기존 모델의 선언 뒤에 model.cuda() 를 실행하여 모델 전체를 GPU 메모리에 올린다. 이후부터 모델의 연산은 모두 GPU 가속을 활용하게 된다. 코드를 실행하면 cuda() 함수를 지나는 시간이 꽤 걸리는 모습을 볼 수 있는데, 모델의 모든 파라미터를 GPU 메모리에 올리고 있기 때문이다.
GPU 메모리에 올라간 모델에 입력되는 텐서 또한 모두 GPU에 올려서 사용해야 한다. GPGPU 챕터에서 이야기했듯이, 모든 CUDA 연산은 GPU 메모리 내의 데이터들만을 가지고 이루어지기 때문이다. 같은 이유로 정답 레이블 텐서도 GPU 메모리에 올라가야 한다. MNISTDataset의 학습 데이터를 불러오는 부분 이후에 GPU 메모리에 적재하는 부분을 추가한다.
def __getitem__(self, idx):
image = cv2.imread(os.path.join(self.dir, self.images[idx]))
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = np.reshape(image, (28*28)).astype('float32') / 255.0
label = self.labels[idx]
image = torch.as_tensor(image)
label = torch.as_tensor(label).long()
return image.cuda(), label.cuda() # GPU에 적재한 텐서를 반환
모델에 입력되는 데이터와 정답 레이블 또한 GPU 메모리에 적재되어, GPU 가속을 이용하면서 모델을 최적화할 수 있게 되었다. MNISTDataset을 직접 수정했기 때문에, 모델의 평가 과정도 자동으로 GPU 가속을 활용하게 된다.
아직 모델과 데이터가 크지 않아, GPU를 이용한 학습 속도가 비슷하거나 오히려 더 느릴 수도 있다. GPU로 연산 흐름이 갔다 오는 병목이 오히려 더 크기 때문이다. 그러나 이후 더 크고 복잡한 모델을 학습하게 되면 GPU 가속이 비교도 안될 정도로 빠른 학습을 가능케 한다. 복잡한 모델을 학습해보는 챕터 4부터 GPU 가속의 진가를 느낄 수 있을 것이다.
PyTorch 모델을 저장하고 불러오기
드디어 손 글씨 분류기라는, 실제로 쓸모가 있을 법한 딥 러닝 모델을 만들어보았다. 이 모델을 학습해서 평가 정확도만 확인하면 의미가 없다. 실제로 모델을 배포해서 어딘가에 쓰일 수 있게 만들어야 의미가 있을 것이다. 때문에 대부분의 딥 러닝 프레임워크는 학습한 모델을 그대로 저장하고 다시 불러올 수 있는 자신만의 방법을 제공하며, PyTorch도 마찬가지이다.
PyTorch에서 모든 모델과 옵티마이저는 각각 자신만의 state_dict를 가지고 있다. state_dict는 간단히 말해 모델의 모든 레이어와 파라미터의 구조 정보를 가지고 있는 딕셔너리 형태의 자료이다. PyTorch 모델의 state_dict를 출력해 확인할 수 있다.
print(model.state_dict)
<bound method Module.state_dict of Sequential(
(0): Linear(in_features=784, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=256, bias=True)
(3): ReLU()
(4): Linear(in_features=256, out_features=10, bias=True)
)>
정의한 모델의 모든 레이어 정보를 담고 있음을 확인할 수 있다. 그래서 PyTorch로 학습한 모델을 저장할 때는 모델의 state_dict 정보와, 대응하는 모든 가중치 및 편향 파라미터를 연결시켜 저장한다. 학습이 완료된 후 torch.save 함수를 사용해 모델을 저장할 수 있다. 저장되는 파일의 확장자는 .pt 또는 .pth 가 일반적으로 사용된다.
torch.save(model.state_dict(), 'mnist_model.pt')
mnist_model.pt 파일에 학습한 모델의 state_dict와 그에 대응하는 모든 파라미터 값들이 저장된다. 이후에 torch.load 함수를 이용하여 저장된 모델을 불러올 수 있다. 당연히 저장하는 시점과 동일한 구조의 모델이 먼저 정의되어 있어야 한다. 모델의 구조가 다르면 state_dict가 달라지므로 모델을 불러오는 과정에서 에러가 발생한다. PyTorch는 먼저 state_dict 에 저장된 모델 구조와 정의된 모델의 구조가 동일한지 확인하고, 모든 파라미터를 다시 불러온다.
model.load_state_dict(torch.load('./mnist_model.pt'))
model.eval() # 모델을 추론 모드로 변경한다.
모델을 불러와 학습이 아닌 추론을 위해서만 사용한다면, eval 함수를 사용해 모델을 평가 모드로 설정해주어야 한다. 이렇게 하지 않으면 학습 과정에서 랜덤성을 가지는 일부 기능들이 그대로 동작하여, 모델을 실행할 때마다 결과가 바뀌게 된다. 대표적으로 다음 챕터에서 살펴볼 드롭아웃같은 기능들이 있다.
학습 진행 상황을 저장하고 불러오기
마지막으로 학습의 진행 상황을 저장하고, 학습이 중단되어도 나중에 진행 상황을 불러와 학습을 재개할 수 있도록 만들어보자. 모델의 학습 상황을 저장하려면 모델의 state_dict 말고도 현재 옵티마이저의 상황, 진행한 에폭 수 등 다양한 정보를 같이 저장해야 한다. 다행히 torch.save 함수는 여러 정보들을 같이 파일에 묶어 저장할 수 있도록 기능을 제공한다. 학습을 위한 다양한 정보를 통째로 딕셔너리에 묶어 파일에 저장할 수 있다.
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict()
}, 'mnist_model.pt')
모델의 state_dict 말고도 모델의 모든 파라미터 학습 상황과 옵티마이저의 상태 등을 모두 저장한다. 이후 모델 학습을 다시 시작할 때, torch.load 함수로 학습 중단시의 모든 정보를 불러와 학습을 재개할 수 있다.
checkpoint = torch.load('mnist_model.pt')
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
거대한 데이터셋을 사용하거나 매우 큰 모델을 학습하게 되면, 학습의 진행이 느리기 때문에 학습을 중단하고 재시작해야 할 일이 종종 생긴다. 모델의 학습이 오래 걸릴 듯 싶다면 학습 코드를 작성할 때 중간 결과를 저장하고 불러올 수 있도록 코드를 구현해놓으면 좋다.
3.5.3. 모델의 용량
손글씨 이미지라는 복잡한 데이터를 이해하기 위한 딥 러닝 모델을 구현해보았다. 이전 챕터들에서 구현했던 모델들보다 파라미터의 갯수가 확실히 많다. 첫 번째 레이어만 봐도 784 x 256 크기의 텐서다. 입력 데이터가 복잡해진 만큼, 데이터를 이해하기 위해 필요한 파라미터의 개수 또한 늘어나는 것이다. 만약 모델의 전체적인 파라미터 개수를 크게 줄인다면 학습 결과가 어떻게 변할까? 직접 모델을 수정한 후 확인해보자.
model = nn.Sequential(
nn.Linear(784, 20),
nn.ReLU(),
nn.Linear(20, 20),
nn.ReLU(),
nn.Linear(20, 10)
)
이 모델의 학습 결과 정확도는 다음과 같이 비교적 낮게 나온다.
Accuracy: 0.9471
모델의 파라미터 갯수가 줄어드니 분류 정확도가 크게 하락했다. 파라미터의 갯수가 MNIST 데이터셋을 이해할 수 있을만큼 충분하지 않았기 때문이다. 일반적으로 딥 러닝 모델의 입력과 출력 데이터의 형태가 복잡해질수록 모델의 파라미터 갯수도 같이 커져야 한다. 데이터가 복잡하다는 것은 곧 입출력 사이의 관계 또한 복잡한 함수 관계의 조합으로 이루어진다는 뜻이기 때문이다. 함수 관계가 복잡해지는 것은 곧 파라미터 갯수의 증가를 의미한다.
파라미터의 갯수가 많아질수록 모델이 더욱 복잡한 데이터셋을 이해할 수 있게 된다. 이렇게 모델이 이해할 수 있는 데이터의 복잡도를 모델의 용량(Capacity) 이라고 한다. 모델의 파라미터 갯수와 영향이 깊지만, 파라미터 갯수와 용량이 같은 말은 아니다. 모델이 구현하고 있는 입출력 사이 관계 함수가 얼마나 복잡한지를 이야기하는 개념이라고 생각하면 된다. 모델의 복잡도(Complexity) 또한 비슷한 단어로 해석할 수 있다.
앞에서 모델의 파라미터 갯수를 줄임으로써 모델의 용량을 고의적으로 낮췄다. 모델이 표현하는 데이터의 관계가 상대적으로 단순해졌으므로, 정확도가 떨어지는 것은 당연하다. 처음으로 구현했던 모델은 상대적으로 모델의 용량이 크기 때문에 더욱 높은 정확도를 보일 수 있었다.
언더피팅과 오버피팅
모델의 복잡도가 감소해 데이터 이해력이 떨어지는 현상을 언더피팅(Underfitting) 이라고 한다. 모델이 학습 데이터셋에 충분히 적합(fit) 하지 않다는 뜻이다. 반대로 모델의 복잡도가 너무 커서 학습 데이터를 너무 완벽히 이해한 상황을 오버피팅(Overfitting) 이라고 한다. 모델이 학습 데이터셋에 너무 과하게 적합하다는 뜻이다. 언더피팅과 오버피팅 현상을 이해하려면, 딥 러닝 모델의 학습을 일반화(Generalization) 의 관점에서 이해해야 한다.
간단한 이중 분류 문제로 예를 들어보자. 단순히 MNIST 데이터셋에서 0과 1의 두 숫자 이미지만을 구분하는 모델을 만들고자 한다. 차원 축소를 이용해 784차원의 입력 벡터를 2차원으로 줄였다고 가정했을 때, 언더피팅된 모델과 오버피팅된 모델은 대강 다음과 같이 나타날 것이다.
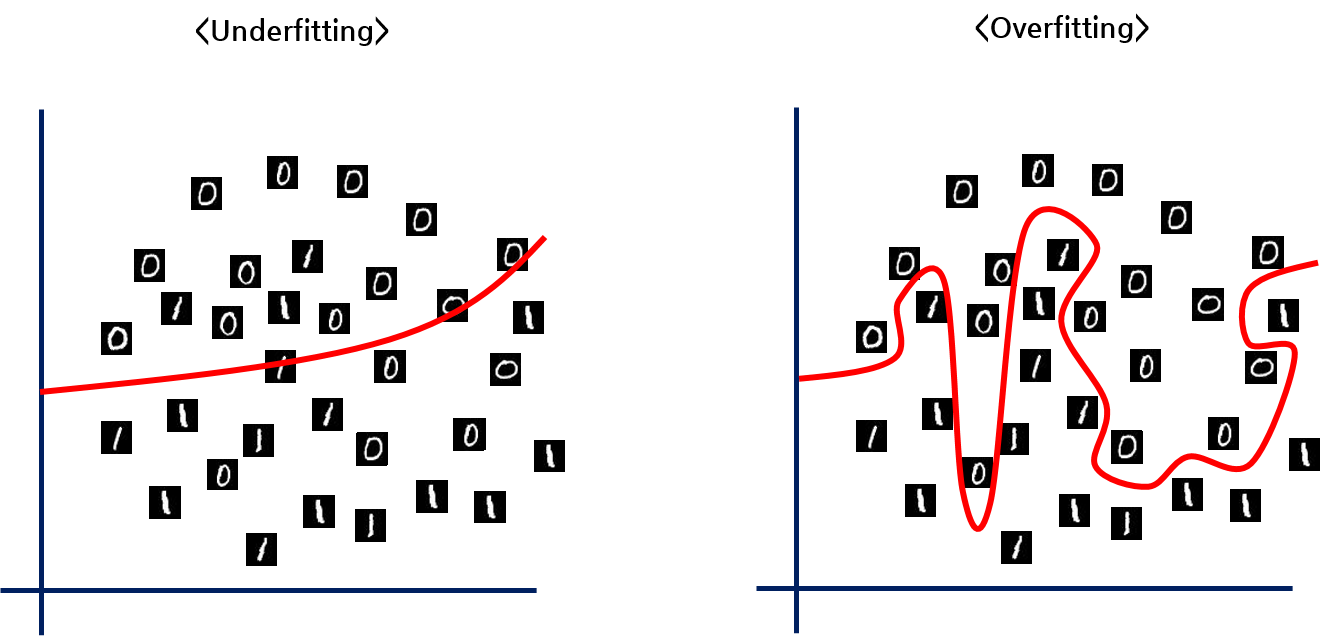
딥 러닝 학습의 목표는, 학습 데이터셋을 통해 최대한 많은 데이터에 대해 일반적인 모델을 찾아내는 것이다. 모델은 기본적으로 학습 데이터셋을 최대한 완벽히 구분하도록 학습하면서, 평가 데이터셋에 대한 구분력도 높게 유지해야 한다. 즉, 최대한 많은 데이터를 잘 구분할 수 있도록 일반화(Generalization) 해야 한다. 언더피팅된 모델은 데이터의 전체적인 분포에서 조금이라도 빗나가면 데이터를 제대로 구분할 수 없다. 학습 데이터셋에 대해 충분한 최적화가 이루어지지 않아서 일반화에 실패한 것이다. 반대로 오버피팅된 모델은 학습 데이터셋에 대해서만 너무 과하게 딱 맞는 결정 경계를 만들어낸다. 학습 데이터셋과 경향이 조금이라도 다른 평가 데이터가 들어오면 분류에 실패할 확률이 커진다. 너무 최적화가 심하게 이루어져서 일반화에 실패하는 케이스다. 오버피팅된 모델은 학습 데이터셋에서의 성능은 매우 좋으나, 일반화에 실패했기 때문에 평가 데이터셋에서의 성능은 한참 떨어지는 현상이 나타난다.
모델의 용량이 너무 크거나 학습 데이터셋이 너무 작은 경우 오버피팅이 발생할 확률이 높다. 학습 데이터셋이 작아지면 그것을 이해하기 위해 필요한 모델의 용량 또한 작아지기 때문에, 같은 크기의 모델이라도 오버피팅이 발생할 확률이 높아진다.
동일한 맥락으로 모델의 크기가 너무 커져도 오버피팅이 발생할 것이다. 딥 러닝 모델의 일반화에 성공하기 위해서는, 데이터를 이해하기 위한 적절한 크기의 모델을 찾아내는 것이 필수다. 적절한 모델을 찾아내는 과정은 대부분 개발자의 경험에 의존하지만, 최근에는 모델 자체를 딥 러닝으로 찾아내는 방법 또한 깊이 연구되고 있다.
모델이 일반화에 실패하는 이유가 모델의 용량에만 있는 것은 아니다. 근본적으로 학습 데이터셋이 불균형할 경우 언더피팅의 가능성이 매우 커진다. 다중 분류 모델을 특정 레이블의 데이터만 많이 포함된 상태로 학습하면, 모델이 상대적으로 보지 못한 데이터에 대해서는 분류 성능이 당연히 떨어질 수 밖에 없다.
정리하자면, 딥 러닝 모델을 효과적으로 학습시키기 위해서는 먼저 데이터셋의 데이터 분포가 충분히 다양하고 균형잡혀있는지 확인해야 한다. 특정 데이터가 불균형하게 많거나 적게 포함된 경우 모델이 충분한 일반화에 실패할 가능성이 크다. 그 후 데이터셋을 이해하기 위한 모델의 용량이 충분한지 확인해야 한다. 적절한 모델의 용량은 실험적으로 구할수밖에 없으므로, 검증 데이터셋을 최대한 활용해 가장 잘 일반화되는 모델을 찾아야 한다.